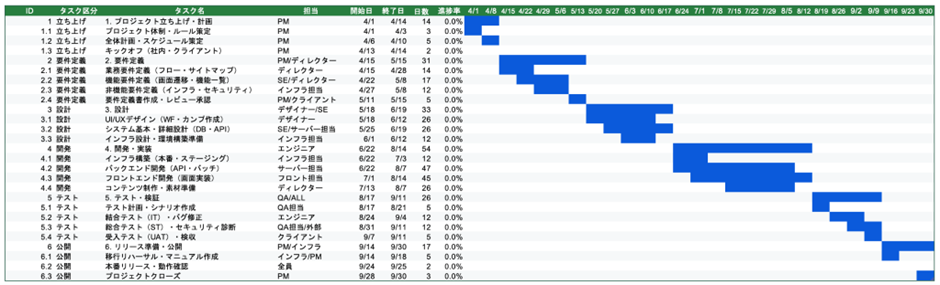
Excelで、セル内の文字列操作って、どうしてますか?
たとえば、業務用資料であれば、商品コードや従業員ID、取引先コードなど、有意なアルファベットと数字を組み合わせた記号/番号群が多用されます。これらの記号/番号から一部を切り取って、分類したり、レコード数を数えたりしたい場合です。
「ABC-1234」というコードがあった場合に、「ABC」と「1234」に切り分けて、別々のセルへ格納するような作業を、どうしてますか?
まさか、いまだに「努力、根性、コピー・ペースト!」ではないですよね?
コードの長さが一律であれば、たとえば区切り位置(ハイフン)左右の文字数をかぞえて、
=LEFT(セル番地,3)
=RIGHT(セル番地,4)
とすれば作業完了です。
しかし、2022年夏からMicrosoft 365版Excelへ実装された”TEXTSPLIT関数”を試してみたら、とても便利でしたので、この記事でご紹介しますね。
※本記事でご紹介するTEXT操作系全関数の構文・使い方のくわしい解説をすると、とても長い説明文となってしまうため省略します。もしリクエストをいただいた場合には、特定関数について、さらにつっこんだ説明記事を別途公開いたします。
Googleスプレッドシートには、もともとSPLIT関数がありました
同様の関数は、Googleのオンライン無料ソフト、”Googleスプレッドシート(以下Gスプレッドシート)”にもあります。
「あります」というよりも、Gスプレッドシートでは、2009年頃からSPLIT関数が使えました。Microsoft 365版ExcelでTEXTSPLIT関数が使えるようになったのは2022年ですが、導入までに10年以上も差があった分、Gスプレットシートを超える便利な設定も用意されているようです。
それでは、まず”TEXTをSPLITする関数”の基本機能とは、具体的にどういうことでしょうか?
ひとことで言えば、[データ]タブ→[区切り位置]メニューの関数版、ということです。
たとえば、他システムからCSV出力したカンマ付きの住所録を、カンマ部分で一括分割するとします。
従来ならば、[データ]タブ→[区切り位置]メニューのウィザードに沿って下図のように分割指示をしていました。
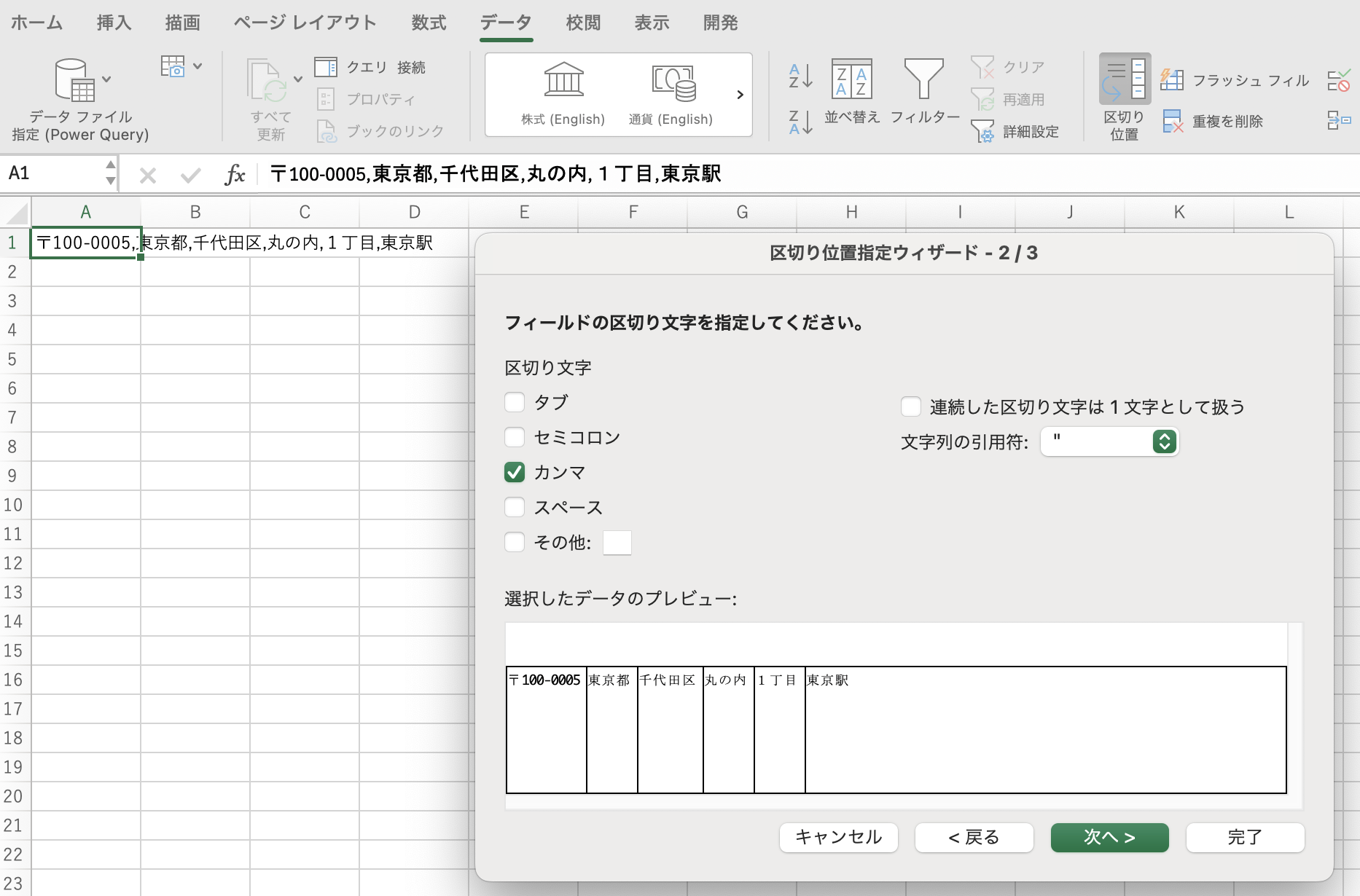
同じ分割作業を、TEXTSPLIT関数を使って行う場合、B1セル(だけ)に
=TEXTSPLIT(A1,”,”)
と入力します。
すると、スピル(数式の結果を自動的に隣接するセルへ展開する機能)が働いて、B1からG1までのセルに分割結果が、(A1へ作業前のカンマ付きテキスト情報を残したまま)自動的に表示されます。

Microsoft公式サポートWebサイトでも、まだ引数情報がすべて英語表記のままですが、TEXTSPLIT関数の基本構文は、
=TEXTSPLIT(text,col_delimiter,[row_delimiter],[ignore_empty], [match_mode], [pad_with])
と説明されており、第3引数以降は省略可能です。
そのため、まずは
=TEXTSPLIT(分割したいテキスト(orそのセル番地),分割するための区切り位置)
と覚えておけば、いろいろな事例に応用できるでしょう。
上図では、区切り位置を”,”と指定しましたが、これをハイフン”-”とすることもできますし、2文字以上の文字列で指定することも可能です。
2文字以上の文字列指定は、Gスプレットシートではできなかった手法で、たとえば、
Sato and Tanaka and Suzuki will join the meeting.
という1文を、GスプレッドシートとExcelで分割してみるとよくわかります。
<Gスプレッドシート>

<Excel>

Gスプレッドシートの場合、複数文字の区切り位置設定ができないため、Satoの「a」を区切り位置の1つとみなしてしまい、おかしな分割結果になってしまっているようですね。
TEXT操作系関数を組み合わせれば、複雑な分割-結合指示も、容易に実行可能です
以下、文字列分割・結合の事例として、郵便番号台帳の整備をイメージしてみましょう。
社内には、顧客や仕入先名簿、従業員住所録など、さまざまな住所情報が存在します。
また、新規顧客からWeb申込みを受けたりして、新たな住所情報が増えることも多いでしょう。
住所は、郵便番号をキーとして検索・集計されることがよくありますが、日本全国すべての郵便番号情報は、郵便局公式Webサイトで、検索できて一覧表ダウンロードも可能です。
しかし、一覧表って、下図のようなCSVなんです。

肝心の郵便番号が、ハイフン無しの7バイト文字列のみ。社内の住所録と付け合わせをする時には、この郵便番号リストでは、不便ですよね?
TEXTSPLIT関数と兄弟姉妹分にあたるTEXT操作系関数を駆使すれば、この7バイトから、必要な情報をいくらでも取り出すことができるようになります。
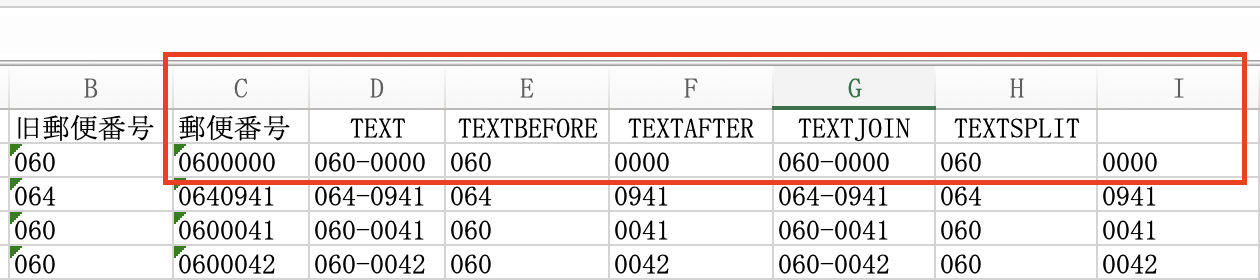
上図で、まずはセルC2に入っているハイフン無しの7バイト文字列について、一般的な郵便番号表記へ変換するため、
=TEXT(C2,”000-0000”)
という関数式を入力します(第2引数の”000-0000”では、文字列の「表示形式」を指定)。
「0600000」という7バイト文字列は、「060-0000」という郵便番号表示に変換されました。
次に、
=TEXTBEFORE(C2,”-”,1)
という関数式を入力します。
旧郵便番号にあたるアタマ3ケタだけが、自動的に抜き出されました。
(旧郵便番号は3ケタと決まっているので、=LEFT(C2,3)でも同じ結果を得られますが、TEXTBEFOREは、ケタ数不問で指定文字より前の文字列を一括抽出します。バイト数不定のメールアドレスについて、@ドメイン名以前のユーザーネームのみを正確に抽出する際などにも、威力を発揮します)。
※TEXTAFTER関数はTEXTBEFOREの逆、つまり区切り位置より後の情報を抽出します。
一度、「060」と「0000」に分解した郵便番号の一部を、今度はTEXTJOIN関数で再結合してみましょう。
=TEXTJOIN(”-”,TRUE,E2,F2)
分解された2要素は、再結合されて、正規郵便番号表記(「060-0000」)に戻りました。
最後に、TEXTJOINされた文字列を、再びTEXTSPLIT関数を用いて、区切り位置;ハイフン”-”で前後に分割してみました。
=TEXTSPLIT(G2,”-“)
ここでもスピルが働いて、ハイフン前後が2列に真っ二つです。
いかがでしょうか?
単なる7バイト文字列も、ここまで自由自在に表示変更、抽出、分割、再結合できれば、どのような他データベースにも適合させられるリストが、容易に作成できるのではないでしょうか?
まとめ;TEXTSPLIT関数は[区切り位置]指定だけの関数にあらず!ほかのTEXT系諸関数とうまく組み合わせれば、文字列操作が自由自在に!
TEXTSPLITやTEXTBEFORE、TEXTAFTERなどの新関数を使わないで文字列の分割作業をする場合、おそらく先にあげたLEFTやRIGHTとMID、さらにはSUBSTITUTEやCONCATなどを組み合わせることになるでしょう。
その場合には、元レコードのバイト数を、事前に把握しておく必要があります。
不明な場合は、さらに「バイト数を数える」関数を入れ子にするので、より面倒な関数式になりがちです。
しかし、TEXT系の関数では、[区切り位置][結合位置]などを引数で指定すれば、バイト数不定の元レコードでも、自在に分割・結合作業が進められます。業務内容が複雑になり、業務コード体系も複雑になればなるほど、旧来の関数によるコード操作には限界がでますので、ぜひTEXTSPLITをはじめとした新関数を、うまく使いこなしてみてくださいね。
そうすることで、「努力、根性、コピー・ペースト!」にたよらない資料作成ができるかもしれませんよ。